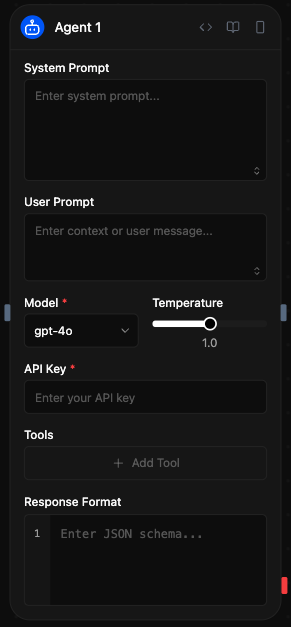
Visão geral
O bloco Agente permite:Opções de configuração
Prompt do sistema
O prompt do sistema estabelece os parâmetros operacionais e as restrições de comportamento do agente. Esta configuração define o papel do agente, a metodologia de resposta e os limites de processamento para todas as solicitações recebidas.Prompt do usuário
O prompt do usuário representa os dados de entrada principais para o processamento de inferência. Este parâmetro aceita texto em linguagem natural ou dados estruturados que o agente analisará e aos quais responderá. As fontes de entrada incluem:- Configuração estática: Entrada de texto direta especificada na configuração do bloco
- Entrada dinâmica: Dados passados de blocos anteriores através de interfaces de conexão
- Geração em tempo de execução: Conteúdo gerado programaticamente durante a execução do fluxo de trabalho
Seleção de modelo
O bloco Agente suporta múltiplos provedores de LLM através de uma interface de inferência unificada. Os modelos disponíveis incluem:- Modelos OpenAI: GPT-5, GPT-4o, o1, o3, o4-mini, gpt-4.1 (inferência baseada em API)
- Modelos Anthropic: Claude 3.7 Sonnet (inferência baseada em API)
- Modelos Google: Gemini 2.5 Pro, Gemini 2.0 Flash (inferência baseada em API)
- Provedores alternativos: Groq, Cerebras, xAI, DeepSeek (inferência baseada em API)
- Implantação local: Modelos compatíveis com Ollama (inferência auto-hospedada)
Temperatura
Controla a criatividade e aleatoriedade das respostas:- Baixa (0-0.3)
- Média (0.3-0.7)
- Alta (0.7-2.0)
Respostas mais determinísticas e focadas. Ideal para tarefas factuais,
atendimento ao cliente e situações onde a precisão é crítica.
O intervalo de temperatura (0-1 ou 0-2) varia dependendo do modelo
selecionado.
Chave API
Sua chave API para o provedor de LLM selecionado. É armazenada de forma segura e utilizada para autenticação.Ferramentas
As ferramentas ampliam as capacidades do agente através de integrações de API externas e conexões de serviços. O sistema de ferramentas permite a chamada de funções, permitindo ao agente executar operações além da geração de texto. Processo de integração de ferramentas:- Acesse a seção de configuração de Ferramentas dentro do bloco do Agente
- Selecione entre mais de 80 integrações predefinidas ou defina funções personalizadas
- Configure os parâmetros de autenticação e as restrições operacionais
- Comunicação: Gmail, Slack, Telegram, WhatsApp, Microsoft Teams
- Fontes de dados: Notion, Google Sheets, Airtable, Supabase, Pinecone
- Serviços web: Firecrawl, Google Search, Exa AI, automação de navegador
- Desenvolvimento: GitHub, Jira, gerenciamento de repositórios e problemas no Linear
- Serviços de IA: OpenAI, Perplexity, Hugging Face, ElevenLabs
- Auto: O modelo determina a invocação de ferramentas de acordo com o contexto e a necessidade
- Obrigatório: A ferramenta deve ser chamada durante cada solicitação de inferência
- Nenhum: Definição de ferramenta disponível mas excluída do contexto do modelo
Formato de resposta
O parâmetro de formato de resposta impõe a geração de saídas estruturadas através da validação de esquemas JSON. Isso garante respostas consistentes e legíveis por máquina que se ajustam a estruturas de dados predefinidas:Acesso aos resultados
Depois que um agente completa sua tarefa, você pode acessar suas saídas:<agent.content>: O texto de resposta ou dados estruturados do agente<agent.tokens>: Estatísticas de uso de tokens (prompt, completado, total)<agent.tool_calls>: Detalhes de qualquer ferramenta que o agente utilizou durante a execução<agent.cost>: Custo estimado da chamada à API (se disponível)
Funcionalidades avançadas
Memória + Agente: Histórico de conversação
Utilize um blocoMemory com um id consistente (por exemplo, chat) para persistir mensagens entre execuções e incluir esse histórico no prompt do agente.
- Adicione a mensagem do usuário antes do agente
- Leia o histórico de conversação para contexto
- Adicione a resposta do agente depois que ele for executado
Memory para mais detalhes.
Entradas e saídas
- Configuração
- Variáveis
- Resultados
- Prompt do sistema: Instruções que definem o comportamento e papel do agente
- Prompt do usuário: Texto ou dados de entrada para processar
- Modelo: Seleção do modelo de IA (OpenAI, Anthropic, Google, etc.)
- Temperatura: Controle de aleatoriedade de resposta (0-2)
- Ferramentas: Array de ferramentas disponíveis para chamadas de funções
- Formato de resposta: Esquema JSON para saída estruturada
Exemplos de casos de uso
Automação de atendimento ao cliente
Cenário: Gerenciar consultas de clientes com acesso a banco de dados
- O usuário envia um ticket de suporte através do bloco API
- O agente verifica pedidos/assinaturas no Postgres e busca na base de conhecimentos
- Se for necessário escalonamento, o agente cria uma ocorrência no Linear com o contexto relevante
- O agente redige uma resposta clara por e-mail
- O Gmail envia a resposta ao cliente
- A conversa é salva no Memory para manter o histórico para mensagens futuras
Análise de conteúdo com múltiplos modelos
Cenário: Analisar conteúdo com diferentes modelos de IA
- O bloco de função processa o documento carregado
- O agente com GPT-4o realiza análise técnica
- O agente com Claude analisa o sentimento e tom
- O bloco de função combina os resultados para o relatório final
Assistente de pesquisa potenciado por ferramentas
Cenário: Assistente de pesquisa com busca web e acesso a documentos
- Consulta do usuário recebida através de entrada
- O agente busca na web utilizando a ferramenta de Google Search
- O agente acessa o banco de dados do Notion para documentos internos
- O agente compila um relatório de pesquisa completo
Melhores práticas
- Seja específico nos prompts do sistema: Defina claramente o papel do agente, o tom e as limitações. Quanto mais específicas forem suas instruções, melhor o agente poderá cumprir seu propósito pretendido.
- Escolha a configuração de temperatura adequada: Use configurações de temperatura mais baixas (0-0.3) quando a precisão é importante, ou aumente a temperatura (0.7-2.0) para respostas mais criativas ou variadas
- Aproveite as ferramentas de forma eficaz: Integre ferramentas que complementem o propósito do agente e melhorem suas capacidades. Seja seletivo sobre quais ferramentas você fornece para evitar sobrecarregar o agente. Para tarefas com pouco sobreposição, use outro bloco de Agente para obter os melhores resultados.