Visão Geral
O bloco Guardrails permite:Corresponder a padrões Regex: Verifica se o conteúdo
corresponde a formatos específicos (e-mails, números de telefone, URLs,
etc.)
Detectar alucinações: Utiliza pontuação RAG + LLM para
validar as saídas de IA contra o conteúdo da base de conhecimentos
Tipos de validação
Validação JSON
Valida se o conteúdo tem um formato JSON adequado. Perfeito para garantir que as saídas estruturadas de LLM possam ser analisadas com segurança. Casos de uso:- Validar respostas JSON de blocos Agent antes de analisá-las
- Garantir que as cargas úteis de API estejam corretamente formatadas
- Verificar a integridade de dados estruturados
passed:truese for JSON válido,falsecaso contrárioerror: Mensagem de erro se a validação falhar (ex.: “JSON inválido: Token inesperado…”)
Validação Regex
Verifica se o conteúdo corresponde a um padrão de expressão regular especificado. Casos de uso:- Validar endereços de e-mail
- Verificar formatos de números de telefone
- Verificar URLs ou identificadores personalizados
- Aplicar padrões de texto específicos
- Padrão Regex: A expressão regular para comparar (ex.:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$para e-mails)
passed:truese o conteúdo corresponder ao padrão,falsecaso contrárioerror: Mensagem de erro se a validação falhar
Detecção de alucinações
Utiliza geração aumentada por recuperação (RAG) com pontuação de LLM para detectar quando o conteúdo gerado por IA contradiz ou não está fundamentado na sua base de conhecimentos. Como funciona:- Consulta sua base de conhecimentos para obter contexto relevante
- Envia tanto a saída da IA quanto o contexto recuperado para um LLM
- O LLM atribui uma pontuação de confiança (escala de 0-10)
- 0 = Alucinação completa (totalmente infundada)
- 10 = Completamente fundamentado (totalmente respaldado pela base de conhecimentos)
- A validação é aprovada se a pontuação ≥ limite (padrão: 3)
- Base de conhecimentos: Selecione entre suas bases de conhecimentos existentes
- Modelo: Escolha LLM para pontuação (requer raciocínio sólido - recomenda-se GPT-4o, Claude 3.7 Sonnet)
- Chave API: Autenticação para o provedor LLM selecionado (oculta automaticamente para modelos hospedados/Ollama)
- Limite de confiança: Pontuação mínima para aprovar (0-10, padrão: 3)
- Top K (Avançado): Número de fragmentos da base de conhecimentos a recuperar (padrão: 10)
passed:truese a pontuação de confiança ≥ limitescore: Pontuação de confiança (0-10)reasoning: Explicação do LLM para a pontuaçãoerror: Mensagem de erro se a validação falhar
- Validar respostas de agentes contra documentação
- Garantir que as respostas de atendimento ao cliente sejam precisas
- Verificar se o conteúdo gerado corresponde ao material de origem
- Controle de qualidade para aplicações RAG
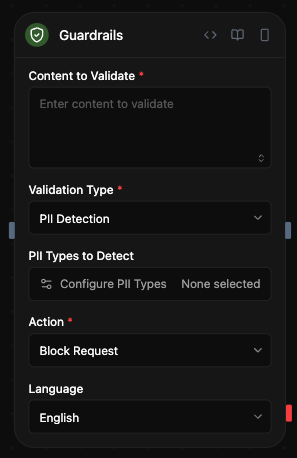
Detecção de PII
Detecta informações de identificação pessoal utilizando Microsoft Presidio. Compatível com mais de 40 tipos de entidades em múltiplos países e idiomas. Como funciona:- Escaneia o conteúdo em busca de entidades PII através de correspondência de padrões e PLN
- Retorna as entidades detectadas com localizações e pontuações de confiança
- Opcionalmente mascara a PII detectada na saída
- Tipos de PII a detectar: Selecione de categorias agrupadas através de seletor modal
- Comum: Nome de pessoa, E-mail, Telefone, Cartão de crédito, Endereço IP, etc.
- EE.UU.: SSN, Licença de motorista, Passaporte, etc.
- Reino Unido: Número NHS, Número de seguro nacional
- Espanha: NIF, NIE, CIF
- Itália: Código fiscal, Licença de motorista, Código de IVA
- Polônia: PESEL, NIP, REGON
- Singapura: NRIC/FIN, UEN
- Austrália: ABN, ACN, TFN, Medicare
- Índia: Aadhaar, PAN, Passaporte, Número de eleitor
- Modo:
- Detectar: Apenas identificar PII (padrão)
- Mascarar: Substituir PII detectada por valores mascarados
- Idioma: Idioma de detecção (padrão: inglês)
passed:falsese os tipos de PII selecionados forem detectadosdetectedEntities: Array de PII detectada com tipo, localização e confiançamaskedText: Conteúdo com PII mascarada (apenas se modo = “Mask”)error: Mensagem de erro se a validação falhar
- Bloquear conteúdo que contém informações pessoais sensíveis
- Mascarar PII antes de registrar ou armazenar dados
- Conformidade com GDPR, HIPAA e outras regulamentações de privacidade
- Sanear entradas de usuário antes do processamento
Configuração
Conteúdo a validar
O conteúdo de entrada para validar. Isso tipicamente provém de:- Saídas de blocos de agente:
<agent.content> - Resultados de blocos de função:
<function.output> - Respostas de API:
<api.output> - Qualquer outra saída de bloco
Tipo de validação
Escolha entre quatro tipos de validação:- JSON válido: Verificar se o conteúdo é JSON corretamente formatado
- Correspondência Regex: Verificar se o conteúdo corresponde a um padrão regex
- Verificação de alucinações: Validar contra base de conhecimento com pontuação LLM
- Detecção de PII: Detectar e opcionalmente mascarar informações de identificação pessoal
Saídas
Todos os tipos de validação retornam:<guardrails.passed>: Booleano que indica se a validação foi bem-sucedida<guardrails.validationType>: O tipo de validação realizada<guardrails.input>: A entrada original que foi validada<guardrails.error>: Mensagem de erro se a validação falhou (opcional)
<guardrails.score>: Pontuação de confiança (0-10)<guardrails.reasoning>: Explicação do LLM
<guardrails.detectedEntities>: Array de entidades PII detectadas<guardrails.maskedText>: Conteúdo com PII mascarado (se o modo = “Mask”)
Exemplos de casos de uso
Validar JSON antes de analisá-lo
Cenário: Garantir que a saída do agente seja JSON válido
- O agente gera uma resposta JSON estruturada
- Guardrails valida o formato JSON
- O bloco de condição verifica
<guardrails.passed> - Se passar → Analisar e usar dados, Se falhar → Tentar novamente ou lidar com o erro
Prevenir alucinações
Cenário: Validar respostas de atendimento ao cliente
- O agente gera uma resposta à pergunta do cliente
- Guardrails verifica contra a base de conhecimentos de documentação de suporte
- Se a pontuação de confiança ≥ 3 → Enviar resposta
- Se a pontuação de confiança < 3 → Marcar para revisão humana
Bloquear PII em entradas de usuário
Cenário: Sanear conteúdo enviado por usuários
- O usuário envia um formulário com conteúdo de texto
- Guardrails detecta PII (e-mails, números de telefone, SSN, etc.)
- Se PII for detectada → Rejeitar o envio ou mascarar dados sensíveis
- Se não houver PII → Processar normalmente
Validar formato de e-mail
Cenário: Verificar o formato de endereço de e-mail
- O agente extrai o e-mail do texto
- Guardrails valida com um padrão regex
- Se for válido → Usar o e-mail para notificação
- Se não for válido → Solicitar correção
Melhores práticas
- Encadear com blocos de Condição: Use
<guardrails.passed>para ramificar a lógica do fluxo de trabalho de acordo com os resultados de validação - Usar validação JSON antes de analisar: Sempre valide a estrutura JSON antes de tentar analisar as saídas de LLM
- Escolher os tipos de PII apropriados: Selecione apenas os tipos de entidades PII relevantes para seu caso de uso para melhor desempenho
- Estabelecer limites de confiança razoáveis: Para a detecção de alucinações, ajuste o limite de acordo com seus requisitos de precisão (mais alto = mais estrito)
- Usar modelos poderosos para a detecção de alucinações: GPT-4o ou Claude 3.7 Sonnet fornecem uma pontuação de confiança mais precisa
- Mascarar PII para registro: Use o modo “Mask” quando precisar registrar ou armazenar conteúdo que possa conter PII
- Testar padrões regex: Valide seus padrões de expressões regulares minuciosamente antes de implementá-los em produção
- Monitorar falhas de validação: Rastreie as mensagens
<guardrails.error>para identificar problemas comuns de validação
A validação de Guardrails ocorre de forma síncrona no seu fluxo de trabalho.
Para a detecção de alucinações, escolha modelos mais rápidos (como
GPT-4o-mini) se a latência for crítica.